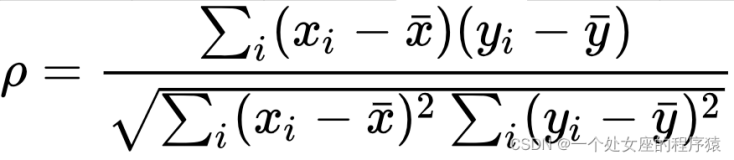#!/usr/local/bin/python2.7
# encoding: utf-8
import sys
import os
from argparse import ArgumentParser
from argparse import RawDescriptionHelpFormatter
from math import sqrt
import moivescore # import module defined by yourself
from rope.base.prefs import Prefs
from bokeh.models.tools import Scroll
# 利用欧几里德距离评价相关性
def sim_distance(prefs,p1,p2):
si = {} # mark the moive name that both appeared p1 and p2
for item in prefs[p1]:
# print(item)
if item in prefs[p2]:
si[item] = 1
# print(si)
if len(si)==0: return 0 # have no same moive
# 利用欧几里德距离评价相关性
sum_of_squares = sum([pow(prefs[p1][item]-prefs[p2][item], 2) for item in prefs[p1] if item in prefs[p2] ])
# print(sum_of_squares)
print(1/(1+sqrt(sum_of_squares)))
return 1/(1+sqrt(sum_of_squares))
# 利用皮尔逊相关系数进行评价,可以修正评分中的夸大分值
def sim_pearson(prefs,p1,p2):
si = {}
for item in prefs[p1]:
if item in prefs[p2]:
si[item] = 1
if len(si)==0: return 0
n = len(si)
# EX
sum1 = sum(prefs[p1][item] for item in si)
# EY
sum2 = sum(prefs[p2][item] for item in si)
# EX2
sqsum1 = sum(pow(prefs[p1][item],2) for item in si)
# EY2
sqsum2 = sum(pow(prefs[p2][item],2) for item in si)
#EXY
psum = sum(prefs[p1][item]*prefs[p2][item] for item in si)
#EXY-EX*EY
num = psum-(sum1*sum2/n)
den = sqrt((sqsum1-pow(sum1,2)/n)*(sqsum2-pow(sum2,2)/n))
if den == 0: return 0
r = num/den
# print(r)
return r
# print(moivescore.critics['Lisa Rose']) # key and value
# print(moivescore.critics['Lisa Rose']['Lady in the Water'])
# sim_distance(moivescore.critics, 'Lisa Rose', 'Gene Seymour')
# sim_distance(moivescore.critics, 'Lisa Rose', 'Michael Phillips')
# sim_distance(moivescore.critics, 'Lisa Rose', 'Claudia Puig')
# sim_distance(moivescore.critics, 'Lisa Rose', 'Mick LaSalle')
# sim_distance(moivescore.critics, 'Lisa Rose', 'Jack Matthews')
# sim_distance(moivescore.critics, 'Lisa Rose', 'Toby')
# sim_distance(moivescore.critics, 'Lisa Rose', 'xiaoYu')
print('--------------------pearson--------------------------------')
# sim_pearson(moivescore.critics, 'Lisa Rose', 'Gene Seymour')
# sim_pearson(moivescore.critics, 'Lisa Rose', 'Michael Phillips')
# sim_pearson(moivescore.critics, 'Lisa Rose', 'Claudia Puig')
# sim_pearson(moivescore.critics, 'Lisa Rose', 'Mick LaSalle')
# sim_pearson(moivescore.critics, 'Lisa Rose', 'Jack Matthews')
# sim_pearson(moivescore.critics, 'Lisa Rose', 'Toby')
# sim_pearson(moivescore.critics, 'Lisa Rose', 'xiaoYu')
# find the person who have the most likely taste with you
def topMatches(prefs,person,n=5,similarity=sim_pearson):
# scores = [other for other in prefs if person!=other]
# print(scores)
scores = [(other,similarity(prefs,person,other)) for other in prefs if person!=other]
# print(scores)
scores.sort()
scores.reverse()
print(scores)
print(scores[0:n])
return scores[0:n] # return existing data from 0 to n
# topMatches(moivescore.critics, 'Lisa Rose', 1)
# use pearson to provide us a recommendation of the film
def getRecommendation(prefs,person,similarity=sim_pearson):
totals={} # sum (similarity*score) all the movie which i havent see
simSums={} # sum similarity of all the movie which i havent see
for other in prefs:
if other == person: continue
sim = similarity(prefs,person,other)
if sim<=0: continue
for item in prefs[other]:
# only estimate the movie this person never watched before, means he has no score on this movie
if item not in prefs[person] or prefs[person][item]==0:
totals.setdefault(item,0)
# similarity*score
totals[item]+=prefs[other][item]*sim
simSums.setdefault(item,0)
simSums[item]+=sim
print(totals)
print(simSums)
# create a ranking list
rankings = [(item,total/simSums[item]) for item,total in totals.items()]
rankings.sort()
rankings.reverse()
print(rankings)
return rankings
getRecommendation(moivescore.critics, 'Toby')